This year’s public data file is now available, featuring over 156 million metadata records deposited with Crossref through the end of April 2024 from over 19,000 members. A full breakdown of Crossref metadata statistics is available here.
Like last year, you can download all of these records in one go via Academic Torrents or directly from Amazon S3 via the “requester pays” method.
Download the file: The torrent download can be initiated here.
Earlier this year, we reported on the roundtable discussion event that we had organised in Frankfurt on the heels of the Frankfurt Book Fair 2023. This event was the second in the series of roundtable events that we are holding with our community to hear from you how we can all work together to preserve the integrity of the scholarly record - you can read more about insights from these events and about ISR in this series of blogs.
Crossref is undertaking a large program, dubbed 'RCFS' (Resourcing Crossref for Future Sustainability) that will initially tackle five specific issues with our fees. We haven’t increased any of our fees in nearly two decades, and while we’re still okay financially and do not have a revenue growth goal, we do have inclusion and simplification goals. This report from Research Consulting helped to narrow down the five priority projects for 2024-2025 around these three core goals:
The Crossref Nominating Committee is inviting expressions of interest to join the Board of Directors of Crossref for the term starting in January 2025. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
Expressions of interest will be due Monday, May 27th, 2024
This is an exciting time to join the board, as we have a number of active projects underway: We are considering resourcing Crossref for a sustainable future and board members will be part of deciding any changes to our fees scheme and overseeing its implementation.
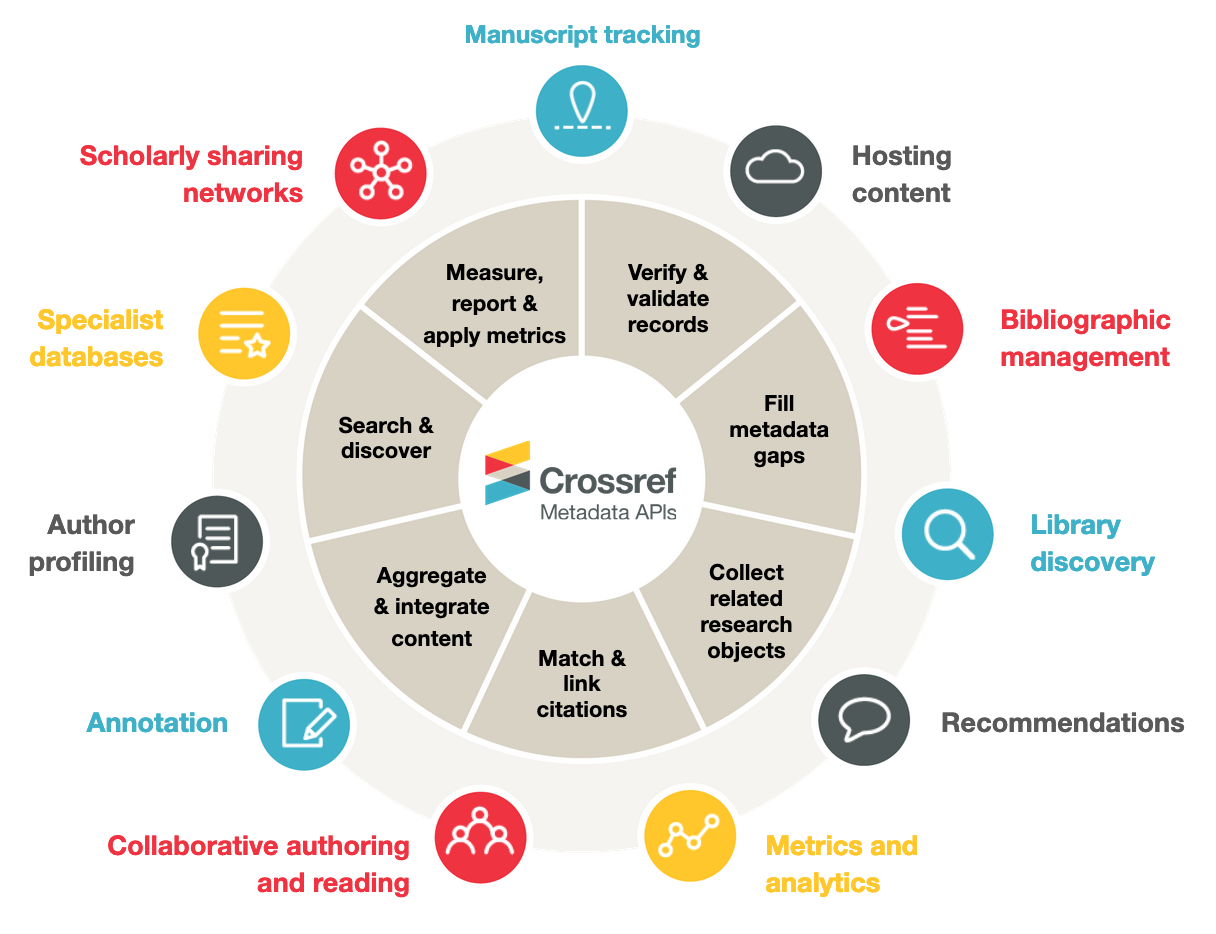
Some of the typical users (outer) and uses (inner) of Crossref metadata
People using Crossref metadata need it for all sorts of reasons including metaresearch (researchers studying research itself such as through bibliometric analyses), publishing trends (such as finding works from an individual author or reviewer), or incorporation into specific databases (such as for discovery and search or in subject-specific repositories), and many more detailed use cases.
All Crossref metadata is open and available for reuse without restriction. Our
158356997 records include information about research objects like articles, grants and awards, preprints, conference papers, book chapters, datasets, and more. The information covers elements like titles, contributors, descriptions, dates, references, connecting identifiers such as Crossref DOIs, ROR IDs and ORCID iDs, together with all sorts of metadata that helps to determine provenance, trust, and reusability—such as funding, clinical trial, and license information.
Anyone can retrieve and use
158356997 records without restriction. So there are no fees to use the metadata but if you really rely on it then you might like to sign up for Metadata Plus which offers greater predictability, higher rate limits, monthly data dumps in XML and JSON, and access to dedicated support from our team.
Options for retrieving metadata
All Crossref metadata is completely open and available to all. Whatever your experience with metadata, there are several tools, techniques, and support guides to help—whether you’re just beginning, exploring occasionally, or need an ongoing reliable integration.
BEGINNING?
You’ve heard Crossref metadata might be useful and want to know where to start.
You rely on Crossref metadata and need to incorporate it into your product at scale.
You might want to jump straight to subscribing to Metadata Plus, which is our premium service for the REST API that comes with monthly data dumps in JSON and XML, higher rate limits, and fast support. But we always recommend that you try out the public version first to make sure it will work for your product. If you’re looking for a single DOI record in multiple formats (e.g. RDF, BibTex, CSL) you can use content negotiation.
Watch the animated introduction to metadata retrieval